Planet Understanding the Amazon from Spaceをやる
Fast.AIのPart1 Lesson3あたり
今回はLesson3あたりで解説されている
Planet: Understanding the Amazon from Spaceをやっていきます。
今回もPaperspaceのGradient°を利用します。
動画やコード、動画の解説は下記リンクを参照してください。
- http://course.fast.ai/lessons/lesson3.html
- https://medium.com/@hiromi_suenaga/deep-learning-2-part-1-lesson-3-74b0ef79e56
- https://github.com/fastai/fastai/blob/master/courses/dl1/lesson2-image_models.ipynb
下準備
KaggleのCLIを使えるようにしてデータをダウンロードし、解凍します。
7zファイルを解凍する必要があるのでついでに解凍用のソフトもインストールします。
!pip install kaggle
!mkdir -p /root/.kaggle
!echo '{"username":"YOUR USER NAME","key":"YOUR TOKEN"}' > /root/.kaggle/kaggle.json
!chmod 600 /root/.kaggle/kaggle.json
!apt-get update
!apt-get install p7zip-full
!kaggle competitions download -c planet-understanding-the-amazon-from-space
!ln -s /root/.kaggle/competitions/ /notebooks/data
import os
os.chdir('/notebooks/data/')
!mv planet-understanding-the-amazon-from-space planet
import os
os.chdir('/notebooks/data/planet/')
!7z x train-jpg.tar.7z
!tar -xvf train-jpg.tar
!7z x test-jpg.tar.7z
!tar -xvf test-jpg.tar
!7z x test-jpg-additional.tar.7z
!tar -xvf test-jpg-additional.tar
#test-jpg-additionalの中身をtest用ディレクトリに追加する。
!mv test-jpg-additional/* test-jpg/
!unzip -o train_v2.csv.zip また、planet.pyを使うのでこのファイルをアップロードしておきます。
実装
まず必要なライブラリをインポートしてPATHを設定します。
import os
os.chdir('/notebooks/')
%reload_ext autoreload
%autoreload 2
%matplotlib inline
from fastai.conv_learner import *
PATH = 'data/planet/'
from fastai.plots import *Submissions will be evaluated based on their mean (F_{2}) score.
と書いてあるのでFast.AI側で用意してれているplanet.pyをインポートしmetricsとしてf2を指定します。
from planet import f2
metrics=[f2]
f_model = resnet34
label_csv = f'{PATH}train_v2.csv'
n = len(list(open(label_csv)))-1検証セット用のインデックスを取得します。 デフォルトでは20%を検証セットにします。
val_idxs = get_cv_idxs(n)データを読み込むための関数を定義します。
今回はMulti-label classificationであり、Dogs vs Cats Reduxのようにサブディレクトリを作って分類することができないので、from_csvを利用します。
(例えば写真1つにつき、agriculture, road, waterのように複数タグが付くためディレクトリ分け不可ということです)
def get_data(sz):
tfms = tfms_from_model(f_model, sz, aug_tfms=transforms_top_down, max_zoom=1.05)
return ImageClassifierData.from_csv(PATH, 'train-jpg', label_csv, tfms=tfms,
suffix='.jpg', val_idxs=val_idxs, test_name='test-jpg')定義した関数からデータを取得し、検証セット用のデータローダからデータを読み出してみます。
data = get_data(256)
x,y = next(iter(data.val_dl))yのデータを見るとone-hot encodingされたデータになっています。
list(zip(data.classes, y[0]))[('agriculture', 1.0),
('artisinal_mine', 0.0),
('bare_ground', 0.0),
('blooming', 0.0),
('blow_down', 0.0),
('clear', 1.0),
('cloudy', 0.0),
('conventional_mine', 0.0),
('cultivation', 0.0),
('habitation', 0.0),
('haze', 0.0),
('partly_cloudy', 0.0),
('primary', 1.0),
('road', 0.0),
('selective_logging', 0.0),
('slash_burn', 0.0),
('water', 1.0)]画像を表示してみます。
plt.imshow(data.val_ds.denorm(to_np(x))[0]);
画像がちょっと暗いので明るくして表示してみます。 各要素はピクセルごとのRGBの値なので単純に乗算すれば明るくなります。
plt.imshow(data.val_ds.denorm(to_np(x))[0]*1.4);
今回扱う画像は犬猫のようにImageNetに存在するようなものではないので、重みデータなどはそのままでは最適化されているとは言えません。 衛星写真は犬や猫とは違うものの、エッジやコーナー、テクスチャのパターンといったものの識別をするレイヤーは有用なのでこれらは利用し、追加した最後レイヤーのみ小さい画像を使ってとりあえず学習させます。
小さい画像から始めることは衛星画像などの非標準のデータを学習する時に有効です。 (動画のこのあたりを参照してください)
data.resizeで画像をリサイズしていますが、これはオリジナルの大きさデータから64x64にリサイズするよりも、予め小さめ画像を作っていたほうが高速なためここで小さなサイズの画像を作成し保存しています。
この処理は必ずしも必要ではありませんが、処理時間を短縮するのに有効です。
sz=64
data = get_data(sz)
data = data.resize(int(sz*1.3), 'tmp')
learn = ConvLearner.pretrained(f_model, data, metrics=metrics)最適なLearning Rateを計算します。
lrf=learn.lr_find()
learn.sched.plot()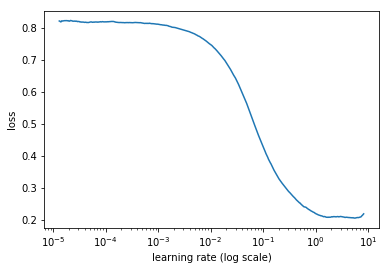
取得したLearning Rateを設定し、学習させます。
lr = 0.2
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)今回の場合、内側のレイヤーは外側のレイヤーよりも有用ですが、まだ学習が必要なためunfreezeを行い、レイヤグループごとに異なるLearning Rateを設定し、さらに学習させます。
Easy steps to train a world-class image classifierで言及されていた
- Unfreeze all layers
- Set earlier layers to 3x-10x lower learning rate than next higher layer. Rule of thumb: 10x for ImageNet like images, 3x for satellite or medical imaging
このあたりですね。 今回は衛星写真なので3xです。
lrs = np.array([lr/9,lr/3,lr])
learn.unfreeze()
learn.fit(lrs, 3, cycle_len=1, cycle_mult=2)画像のサイズを大きくして繰り返します。
sz=128
learn.set_data(get_data(sz))
learn.freeze()
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
learn.unfreeze()
learn.fit(lrs, 3, cycle_len=1, cycle_mult=2)
sz=256
learn.set_data(get_data(sz))
learn.freeze()
learn.fit(lr, 3, cycle_len=1, cycle_mult=2)
learn.unfreeze()
learn.fit(lrs, 3, cycle_len=1, cycle_mult=2)これで学習終わったので、モデルの検証を行いSubmitします。
multi_preds, y = learn.TTA(is_test=True)
preds = np.mean(multi_preds, axis=0)threshold = 0.2
classes = np.array(data.classes, dtype=str)
res = [" ".join(classes[np.where(pp > threshold)]) for pp in preds]
test_fnames = [os.path.basename(f).split(".")[0] for f in data.test_ds.fnames]
test_df = pd.DataFrame(res, index=test_fnames, columns=['tags'])
test_df.to_csv('/notebooks/tmp/sbm2.gz', index_label='image_name', compression='gzip')!kaggle competitions submit -c planet-understanding-the-amazon-from-space -f /notebooks/tmp/sbm.gz -m "first commit"こちらの記事よるとthresholdはF2を最大化する数値を指定すると良いらしいのですが、今回は0.2を設定しました。
https://towardsdatascience.com/kaggle-planet-competition-how-to-land-in-top-4-a679ff0013ba
結果こんな感じでした。
